
神经网络优化和优化算法要点总结
日期:2024-07-01 13:20:21 / 人气:
神经网络相比于传统机器学习的最大的特点在于极大地降低了特征提取的难度。但应用过程中仍然存在两个难点:
- 优化困难:神经网络模型往往拟合的是一个非凸函数,难以找到全局最优值点,且现有的模型大多参数较多,模型复杂,训练效率较低。
- 泛化困难:神经网络拟合能力过强,在训练集上产生过拟合,在训练过程中需要加入正则化防止过拟合。
文章目录
网络优化
难点:
- 网络结构的多样性
- 高维变量的非凸优化:低维非凸优化问题主要难点在于如何初始化参数和逃离局部最优点,而高维非凸优化问题难点之一在于怎么逃离鞍点,鞍点在某些维度上梯度为0,但是最优化的目标是找到所有维度上梯度都为0的点,此外,还有容易陷入平坦最小值,由于神经网络的参数存在一定的冗余性,损失函数的局部最小值附近是一个平坦的区域,称为平坦最小值。
优化算法
梯度下降的各种方法
目前,深层神经网络主要通过梯度下降的方式来进行模型优化,梯度下降具体可以分为:批量梯度下降、随机梯度下降以及小批量梯度下降三种形式。
批量梯度下降:用所有训练数据计算梯度更新值
优点:保证收敛,如果是凸函数则可收敛到全局最小值
缺点:计算速度慢,数据量大则对内存要求高,不能够在线学习
随机梯度下降:每次用一个样本计算梯度更新值
优点:计算速度快,支持在线学习
缺点:计算结果方差大,不抗噪声,难以使用矩阵运算加速
小批量梯度下降:一次用一部分数据(通常选择16,32,64个样本)计算梯度
优点:抗噪声,可使用矩阵运算加速
缺点:batch的大小为超参数,需要调参
总结如下图:

以上明显可以看出小批量梯度下降是最优的选择,也是目前实验使用最为广泛的方法。下面从三个方面详细讨论这种方法:1) 批量大小的选择,2) 学习率
α
\alpha
α的调整 3) 参数更新方向
1) 批量大小(Batch Size)
一般而言,批量大小不影响随机梯度的期望,但是会影响随机梯度的方差,批量越大,方差越小,引入的噪声也越少,训练越稳定,因此可以设置更大的学习率。一个简单有效的方法就是线性缩放规则,当批量大小增加n倍后,学习率也增加n倍,适用于批量大小比较小的时候。
2)学习率调整
2.1)学习率衰减(Learning Rate Decay)
也被称为学习率退火(Learning Rate Annealing),简单来说就是在学习的过程中逐渐降低学习率,方法较多,下面展示一下多种学习率衰减方法的效果图:

2.2) 学习率预热(Learning Rate Warmup)
在批量较大时,学习率也较大,但由于一开始学习上参数是随机初始化的,梯度往往较大,如果此时使用较大的学习率则会使得训练不稳定。为了提高训练的稳定性,则在最初的几轮迭代中使用较小的学习率,等梯度下降到一定程度后再调高学习率。一种常用的方式就是逐渐预热,假设预热的波数是
T
′
T'
T′,初始学习率是
α
0
\alpha_0
α0?,则预热过程中每次更新学习率为
α
t
′
=
t
T
′
α
0
\alpha_t'=\frac{t}{T'}\alpha_0
αt′?=T′t?α0?
预热完成后,再选择一种学习率衰减方法来降低学习率。
2.3)周期性学习率调整
为了使得梯度下降方法能够逃离局部最小值或鞍点,一种经验性的方式是在训练过程中周期性地增大学习率。虽然增加学习率可能短期内有损网络的收敛稳定性,但从长期来看有助于找到更好的局部最优解。周期性学习率调整可以使得梯度下降方法在优化过程中跳出尖锐的局部极小值,虽然会短期内会损害优化过程,但最终会收敛到更加理想的局部极小值。主要介绍两种方法:循环学习率和带热重启的随机梯度下降。效果图如下:

2.4)AdaGrad( Adaptive Gradient)
在标准的梯度下降方法中,每个参数在每次迭代时都使用相同的学习率。由于每个参数的维度上收敛速度都不相同,因此根据不同参数的收敛情况分别设置学习率,AdaGrad算法借鉴L2正则化的思想,每次迭代时自适应地调整每个参数的学习率。在第t迭代时,先计算每个参数梯度平方的累计值:
在 Adagrad算法中,如果某个参数的偏导数累积比较大,其学习率相对较小;
相反,如果其偏导数累积较小,其学习率相对较大。但整体是随着迭代次数的增
加,学习率逐渐缩小。Adagrad 算法的缺点是在经过一定次数的迭代依然没有找到最优点时,由于这时的学习率已经非常小,很难再继续找到最优点。
2.5)RMSprop 算法
RMSprop算法是 一种自适应学习率的方法,可以在有些情况下避免 AdaGrad 算法中学习率不断单调下降以至于过早衰减的缺点。

更详细的对比参考深度学习最全优化方法总结比较(SGD,Adagrad,Adadelta,Adam,Adamax,Nadam)。
3)更新方向优化:
3.1)动量法
除了调整学习率之外,还可以通过使用最近一段时间内的平均梯度来代替当前时刻的梯度来作为参数更新的方向
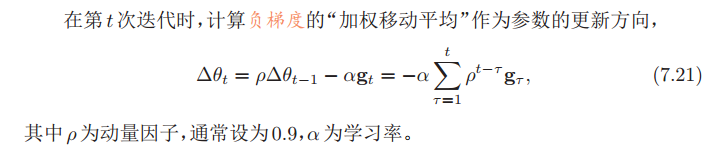
这样,每个参数的实际更新差值取决于最近一段时间内梯度的加权平均值。当某个参数在最近一段时间内的梯度方向不一致时,其真实的参数更新幅度变小;相反,当在最近一段时间内的梯度方向都一致时,其真实的参数更新幅度变大,起到加速作用。一般而言,在迭代初期,梯度方向都比较一致,动量法会起到加速作用,可以更快地到达最优点。在迭代后期,梯度方向会取决不一致,在收敛值附近震荡,动量法会起到减速作用,增加稳定性。
3.2)Adam算法( Adaptive Moment Estimation)
自适应动量估计 ( Adaptive Moment Estimation,Adam)算法可以看作是动量法和 RMSprop的结合,不但使用动量作为参数更新方向,而且可以自适应调整学习率。
Adam算法一方面计算梯度平方
g
t
2
g_t^2
gt2?的指数加权平均(和 RMSprop类似),另
一方面计算梯度
g
t
g_t
gt? 的指数加权平均(和动量法类似)。
M
t
=
β
1
M
t
?
1
+
(
1
?
β
1
)
g
t
M_t=\beta_1M_{t-1}+(1-\beta_1)g_t
Mt?=β1?Mt?1?+(1?β1?)gt?
G
t
=
β
2
G
t
?
1
+
(
1
?
β
2
)
g
t
?
g
t
G_t=\beta_2G_{t-1}+(1-\beta_2)g_t\bigodot g_t
Gt?=β2?Gt?1?+(1?β2?)gt??gt?
M
t
M_t
Mt?可以看作是梯度的均值,
G
t
G_t
Gt?可以看作是均值的为减去均值的方差,迭代初期
M
t
M_t
Mt?和
G
t
G_t
Gt?的值会比真实的均值和方差要小,因此需要对偏差进行修正。

3.3)梯度截断
梯度爆炸也是影响学习率的主要因素,当梯度突然增大,用大的梯度进行梯度进行参数更新时,反而会使得其远离最优点,为了避免这种情况,当梯度的值大于一定的阈值后就对梯度进行截断,称为梯度截断。截断有两种方式,一种是按值截断一种是按模截断。
按值截断:
g
t
=
m
a
x
(
m
i
n
(
g
t
,
b
)
,
a
)
g_t=max(min(g_t, b), a)
gt?=max(min(gt?,b),a)
按模截断:
g
t
=
b
∣
∣
g
t
∣
∣
g
t
g_t=\frac{b}{||g_t||}g_t
gt?=∣∣gt?∣∣b?gt?
主要参考:
邱锡鹏《神经网络与深度学习》


