
3.1 Optimum加速推理
日期:2024-08-26 05:40:36 / 人气:
当前已更新至,3.2 Gradio搭建演示系统
前面的章节中,我们已经进行了一些实战的内容,第三章中,我们将介绍如何将训练好的模型进行应用,主要包括推理加速与服务搭建两部分。这一章节中,我们的关注重点是如何进行模型的推理加速。
之前,我也有写过几篇关于使用onnxruntime进行bert模型推理加速的文章,感兴趣的小伙伴可以看下~
BERT模型压缩、推理、部署在使用onnxruntime进行模型推理加速时,需要我们先将模型转出为onnx格式,并调用onnxruntime库的优化代码来进行优化加速,最后自行实现onnxruntime的推理代码,这无疑还是增加了一些额外的学习成本的。
那么有没有可能只使用一套代码便可以完成上述工作呢?答案是可以的,可以使用Optimum工具包进行实现。
https://github.com/huggingface/optimumOptimum是huggingface开源的模型加速项目,可以与transformers无缝结合,同时支持多种类型的后端,可以根据硬件设备自行选择。
由于前面有一些onnxruntime的基础,因此本章节中将使用Optimum结合onnxruntime进行模型推理加速。
下面让我们开始吧!
本章节的实验仍然使用colab平台,我们需要安装对应的包,optimum包需要指定onnxruntime的后端,这里我们安装onnxruntime的GPU的版本。
pip install transformers optimum[onnxruntime-gpu]如果只使用CPU,则无需-gpu的后缀
pip install transformers optimum[onnxruntime]我们先将原生的pytorch模型进行基准评估,我们使用pipeline进行文本分类任务,模型为uer/roberta-base-finetuned-dianping-chinese。
import times
from transformers import AutoTokenizer, pipeline, AutoModelForSequenceClassification
# 加载分词器与模型
tokenizer = AutoTokenizer.from_pretrained("uer/roberta-base-finetuned-dianping-chinese")
model = AutoModelForSequenceClassification.from_pretrained("uer/roberta-base-finetuned-dianping-chinese")
# 创建pipeline
hf_classifier = pipeline("text-classification", model=model, tokenizer=tokenizer, device=0)这里需要注意,在使用GPU时,pipeline中需要指定device参数,值为显卡的id,默认值是-1,表示不使用GPU。 接下来,我们让其循环测试1000次,并计算平均的推理时间,这里得到时间大概是9.2ms左右。
times = []
for i in range(1000):
start = time.time()
result = hf_classifier("这本书的内容是真不错!强烈推荐大家都看看!")
times.append(time.time() - start)
print("mean time: {}ms".format(sum(times)))
下面,让我们借助Onnxruntime进行推理加速,还记得在开篇中提到的可以与transformers可以无缝结合嘛,这里只需要两行代码便可以得到一个使用Onnxruntime后端加速的模型!
# 1.导包
from optimum.onnxruntime import ORTModelForSequenceClassification
# 2.加载模型
ortmodel = ORTModelForSequenceClassification.from_pretrained("uer/roberta-base-finetuned-dianping-chinese", from_transformers=True)和正常加载模型完全一样有没有!只要导入optimum中对应的ORT模型,并加加载的时候指定from_transformers参数为True,就可以任意的加载官网中的模型。
此外,在具体的使用上,和原生模型也没有差异,直接使用pipeline指定model即可!
onnx_classifier = pipeline("text-classification", model=ortmodel, tokenizer=tokenizer, device=0)同样的,我们也来循环测试1000次,可以看到此时的平均推理时间达到了4.3ms,时间上缩短了一半!
import time
times = []
for i in range(1000):
start = time.time()
result = onnx_classifier("这本书的内容是真不错!强烈推荐大家都看看!")
times.append(time.time() - start)
print("mean time: {}ms".format(sum(times))) 
重点是,我们并没有写过多额外的代码,甚至转换都没有,就完成了推理加速,确实是十分方便了!
当然,除了直接使用外,模型优化与半精度推理也是不可少的,借助optimum我们也可以直接实现,话不多少,直接上代码
from optimum.onnxruntime.configuration import OptimizationConfig
from optimum.onnxruntime.optimization import ORTOptimizer
# 优化器配置
optimization_config = OptimizationConfig(
optimization_level=2, # 优化等级
optimize_for_gpu=True, # 是否面向GPU
fp16=True # 是否转换为半精度
)
# 创建优化器
optimizer = ORTOptimizer.from_pretrained(
"uer/roberta-base-finetuned-dianping-chinese", feature="sequence-classification"
)
# 导出模型
optimizer.export(
onnx_model_path="https://zhuanlan.zhihu.com/p/onnx/model.onnx",
onnx_optimized_model_output_path="https://zhuanlan.zhihu.com/p/onnx/model-optimized.onnx",
optimization_config=optimization_config,
)
# 保存模型配置文件
optimizer.model.config.save_pretrained("https://zhuanlan.zhihu.com/p/onnx")执行完成后,可以看到对应文件夹下便产生了对应的文件
借助ORTModelForSequenceClassification我们可以直接进行模型的加载,需要指定要加载的模型文件。
ort_opt_model = ORTModelForSequenceClassification.from_pretrained("https://zhuanlan.zhihu.com/p/onnx", file_name="model-optimized.onnx")
opt_onnx_classifier = pipeline("text-classification", model=ort_opt_model, tokenizer=tokenizer, device=0)同样的,我们也来循环测试1000次,此时的时间又进一步缩减到了2.6ms,效果非常明显。
times = []
for i in range(1000):
start = time.time()
result = opt_onnx_classifier("这本书的内容是真不错!强烈推荐大家都看看!")
times.append(time.time() - start)
print("mean time: {}ms".format(sum(times)))
我们来完整对比一下整体的结果,从原生模型9.2ms到优化后的2.6ms,推理时长有了明显的下降。
当然这背后还是依赖于onnxruntime的,optimum只是提供了一种非常便捷的调用方式,可以让我们不用刻意了解onnx相关的内容,同时也不需要额外实现推理的代码。
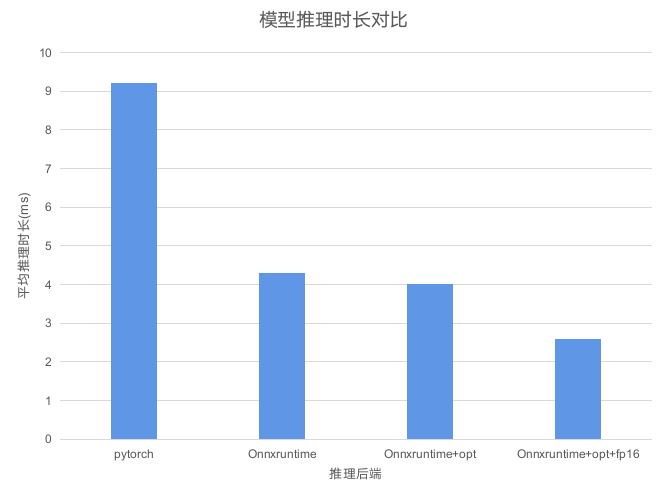
(PS:图中的Onnxruntime+opt是在优化时关闭了fp16的模型,直接将optimization_config中的fp16参数False即可)
最后,给出实验的完整代码
from transformers import AutoTokenizer, pipeline, AutoModelForSequenceClassification
from optimum.onnxruntime import ORTModelForSequenceClassification
# 基准
tokenizer = AutoTokenizer.from_pretrained("uer/roberta-base-finetuned-dianping-chinese")
model = AutoModelForSequenceClassification.from_pretrained("uer/roberta-base-finetuned-dianping-chinese")
hf_classifier = pipeline("text-classification", model=model, tokenizer=tokenizer, device=0)
times = []
for i in range(1000):
start = time.time()
result = hf_classifier("这本书的内容是真不错!强烈推荐大家都看看!")
times.append(time.time() - start)
print("mean time: {}ms".format(sum(times)))
# 直接调用onnxruntime加载
from optimum.onnxruntime import ORTModelForSequenceClassification
ortmodel = ORTModelForSequenceClassification.from_pretrained("uer/roberta-base-finetuned-dianping-chinese", from_transformers=True)
onnx_classifier = pipeline("text-classification", model=ortmodel, tokenizer=tokenizer, device=0)
import time
times = []
for i in range(1000):
start = time.time()
result = onnx_classifier("这本书的内容是真不错!强烈推荐大家都看看!")
times.append(time.time() - start)
print("mean time: {}ms".format(sum(times)))
# onnxruntime优化
from optimum.onnxruntime.configuration import OptimizationConfig
from optimum.onnxruntime.optimization import ORTOptimizer
# 优化器配置
optimization_config = OptimizationConfig(
optimization_level=2, # 优化等级
optimize_for_gpu=True, # 是否面向GPU
fp16=True # 是否转换为半精度
)
# 创建优化器
optimizer = ORTOptimizer.from_pretrained(
"uer/roberta-base-finetuned-dianping-chinese", feature="sequence-classification"
)
# 导出模型
optimizer.export(
onnx_model_path="https://zhuanlan.zhihu.com/p/onnx/model.onnx",
onnx_optimized_model_output_path="https://zhuanlan.zhihu.com/p/onnx/model-optimized.onnx",
optimization_config=optimization_config,
)
# 保存模型配置文件
optimizer.model.config.save_pretrained("https://zhuanlan.zhihu.com/p/onnx")
ort_opt_model = ORTModelForSequenceClassification.from_pretrained("https://zhuanlan.zhihu.com/p/onnx", file_name="model-optimized.onnx")
opt_onnx_classifier = pipeline("text-classification", model=ort_opt_model, tokenizer=tokenizer, device=0)
times = []
for i in range(1000):
start = time.time()
result = opt_onnx_classifier("这本书的内容是真不错!强烈推荐大家都看看!")
times.append(time.time() - start)
print("mean time: {}ms".format(sum(times)))本小节中,我们介绍了Optimum工具包的基本使用,如何使用Optimum工具包结合Onnxruntime进行模型推理加速,但是Optimum能做的还远不止这些,还支持量化与训练加速,这些内容感兴趣的小伙伴们可以自行查阅~
下一章节中,将带来服务搭建的内容,敬请期待吧!


